This package provides representative standard load profiles (SLPs) for electricity published by the German Association of Energy and Water Industries (BDEW Bundesverband der Energie- und Wasserwirtschaft e.V.) in a tidy format. Covers the 1999 profiles â households (H0), commerce (G0â G6), and agriculture (L0â L2) â and the updated 2025 profiles (H25, G25, L25, P25, S25), which additionally represent households with photovoltaic systems and battery storage. Also provides an interface for generating a standard load profile over a user-defined date range. The 1999 data and methodology are described in VDEW (1999), "Repräsentative VDEW-Lastprofile", <https://www.bdew.de/media/documents/1999_Repraesentative-VDEW-Lastprofile.pdf>. The generation algorithm is described in VDEW (2000), "Anwendung der Repräsentativen VDEW-Lastprofile step-by-step", <https://www.bdew.de/media/documents/2000131_Anwendung-repraesentativen_Lastprofile-Step-by-step.pdf>. The 2025 profiles are described in BDEW (2025), "Standardlastprofile Strom", <https://www.bdew.de/energie/standardlastprofile-strom/>.
An exact method for computing the Poisson-Binomial Distribution (PBD). The package provides a function for generating a random sample from the PBD, as well as two distinct approaches for computing the density, distribution, and quantile functions of the PBD. The first method uses direct-convolution, or a dynamic-programming approach which is numerically stable but can be slow for a large input due to its quadratic complexity. The second method is much faster on large inputs thanks to its use of Fast Fourier Transform (FFT) based convolutions. Notably in this case the package uses an exponential shift to practically guarantee the relative accuracy of the computation of an arbitrarily small tail of the PBD -- something that FFT-based methods often struggle with. This ShiftConvolvePoiBin method is described in Peres, Lee and Keich (2020) <arXiv:2004.07429> where it is also shown to be competitive with the fastest implementations for exactly computing the entire Poisson-Binomial distribution.
__This package is deprecated__. Please, use genByteString from the [random package (version >=1.2)](https://hackage.haskell.org/package/random) instead. . Efficient generation of random bytestrings. The implementation populates uninitialized memory with uniformily distributed random 64 bit words (and 8 bit words for remaining bytes at the end of the bytestring). . Random words are generated using the PRNG from the [mwc-random](https://hackage.haskell.org/package/mwc-random) package or the [pcg-random](https://hackage.haskell.org/package/pcg-random) package. It is also possible to use a custom PRNG by providing an instance for the RandomWords type class and using the function generate from the module "Data.ByteString.Random.Internal". . The generated byte strings are suitable for statistical applications. They are /not/ suitable for cryptographic applications. . 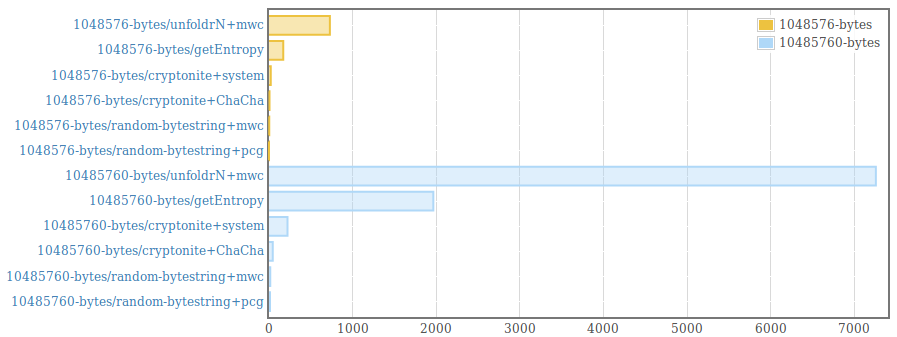 . 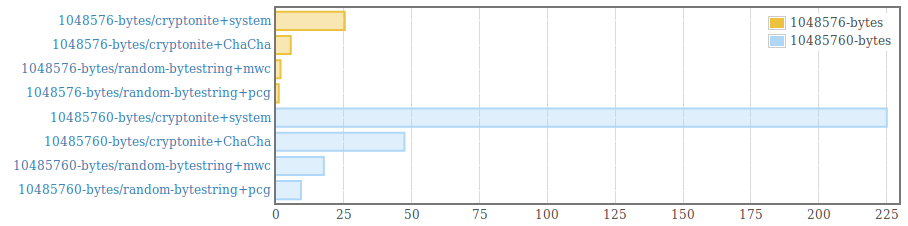
The Importance Index (I.I.) can determine the loss and solution sources for a system in certain knowledge areas (e.g., agronomy), when production (e.g., fruits) is known (Demolin-Leite, 2021). Events (e.g., agricultural pest) can have different magnitudes (numerical measurements), frequencies, and distributions (aggregate, random, or regular) of event occurrence, and I.I. bases in this triplet (Demolin-Leite, 2021) <https://cjascience.com/index.php/CJAS/article/view/1009/1319>. Usually, the higher the magnitude and frequency of aggregated distribution, the greater the problem or the solution (e.g., natural enemies versus pests) for the system (Demolin-Leite, 2021). However, the final production of the system is not always known or is difficult to determine (e.g., degraded area recovery). A derivation of the I.I. is the percentage of Importance Index-Production Unknown (% I.I.-PU) that can detect the loss or solution sources, when production is unknown for the system (Demolin-Leite, 2024) <DOI:10.1590/1519-6984.253218>.
This package provides methods for model-based clustering of multinomial counts under the presence of covariates using mixtures of multinomial logit models, as implemented in Papastamoulis (2023) <DOI:10.1007/s11634-023-00547-5>. These models are estimated under a frequentist as well as a Bayesian setup using the Expectation-Maximization algorithm and Markov chain Monte Carlo sampling (MCMC), respectively. The (unknown) number of clusters is selected according to the Integrated Completed Likelihood criterion (for the frequentist model), and estimating the number of non-empty components using overfitting mixture models after imposing suitable sparse prior assumptions on the mixing proportions (in the Bayesian case), see Rousseau and Mengersen (2011) <DOI:10.1111/j.1467-9868.2011.00781.x>. In the latter case, various MCMC chains run in parallel and are allowed to switch states. The final MCMC output is suitably post-processed in order to undo label switching using the Equivalence Classes Representatives (ECR) algorithm, as described in Papastamoulis (2016) <DOI:10.18637/jss.v069.c01>.
This package performs estimation and inference on a partially missing target outcome (e.g. gene expression in an inaccessible tissue) while borrowing information from a correlated surrogate outcome (e.g. gene expression in an accessible tissue). Rather than regarding the surrogate outcome as a proxy for the target outcome, this package jointly models the target and surrogate outcomes within a bivariate regression framework. Unobserved values of either outcome are treated as missing data. In contrast to imputation-based inference, no assumptions are required regarding the relationship between the target and surrogate outcomes. Estimation in the presence of bilateral outcome missingness is performed via an expectation conditional maximization either algorithm. In the case of unilateral target missingness, estimation is performed using an accelerated least squares procedure. A flexible association test is provided for evaluating hypotheses about the target regression parameters. For additional details, see: McCaw ZR, Gaynor SM, Sun R, Lin X: "Leveraging a surrogate outcome to improve inference on a partially missing target outcome" <doi:10.1111/biom.13629>.
Derivation tree operations are needed for implementing grammar-based genetic programming and grammatical evolution: Generating a random derivation trees of a context-free grammar of bounded depth, decoding a derivation tree, choosing a random node in a derivation tree, extracting a tree whose root is a specified node, and inserting a subtree into a derivation tree at a specified node. These operations are necessary for the initialization and for decoders of a random population of programs, as well as for implementing crossover and mutation operators. Depth-bounds are guaranteed by switching to a grammar without recursive production rules. For executing the examples, the package BNF is needed. The basic tree operations for generating, extracting, and inserting derivation trees as well as the conditions for guaranteeing complete derivation trees have been presented in Geyer-Schulz (1997, ISBN:978-3-7908-0830-X). The use of random integer vectors for the generation of derivation trees has been introduced in Ryan, C., Collins, J. J., and O'Neill, M. (1998) <doi:10.1007/BFb0055930> for grammatical evolution.
See Miroshnikov and Conlon (2014) <doi:10.1371/journal.pone.0108425>. Recent Bayesian Markov chain Monto Carlo (MCMC) methods have been developed for big data sets that are too large to be analyzed using traditional statistical methods. These methods partition the data into non-overlapping subsets, and perform parallel independent Bayesian MCMC analyses on the data subsets, creating independent subposterior samples for each data subset. These independent subposterior samples are combined through four functions in this package, including averaging across subset samples, weighted averaging across subsets samples, and kernel smoothing across subset samples. The four functions assume the user has previously run the Bayesian analysis and has produced the independent subposterior samples outside of the package; the functions use as input the array of subposterior samples. The methods have been demonstrated to be useful for Bayesian MCMC models including Bayesian logistic regression, Bayesian Gaussian mixture models and Bayesian hierarchical Poisson-Gamma models. The methods are appropriate for Bayesian hierarchical models with hyperparameters, as long as data values in a single level of the hierarchy are not split into subsets.
This package provides functions to calculate commonly used public health statistics and their confidence intervals using methods approved for use in the production of Public Health England indicators such as those presented via Fingertips (<https://fingertips.phe.org.uk/>). It provides functions for the generation of proportions, crude rates, means, directly standardised rates, indirectly standardised rates, standardised mortality ratios, slope and relative index of inequality and life expectancy. Statistical methods are referenced in the following publications. Breslow NE, Day NE (1987) <doi:10.1002/sim.4780080614>. Dobson et al (1991) <doi:10.1002/sim.4780100317>. Armitage P, Berry G (2002) <doi:10.1002/9780470773666>. Wilson EB. (1927) <doi:10.1080/01621459.1927.10502953>. Altman DG et al (2000, ISBN: 978-0-727-91375-3). Chiang CL. (1968, ISBN: 978-0-882-75200-6). Newell C. (1994, ISBN: 978-0-898-62451-9). Eayres DP, Williams ES (2004) <doi:10.1136/jech.2003.009654>. Silcocks PBS et al (2001) <doi:10.1136/jech.55.1.38>. Low and Low (2004) <doi:10.1093/pubmed/fdh175>. Fingertips Public Health Technical Guide: <https://fingertips.phe.org.uk/profile/guidance/supporting-information/PH-methods/>.
A Javascript Ribbit Scheme runtime.
Custom rubocop cops used by Discourse
This package provides the Jester Dataset for package recommenderlab.
This package provides an RDF4J-based implementation of RDF 1.1 concepts.
R Commander plug-in to demonstrate various actuarial and financial risks. It includes valuation of bonds and stocks, portfolio optimization, classical ruin theory, demography and epidemic.
This gem can compare HTML and assert certain elements exists. This is useful when writing tests.
This RSpec plugin can be used to stub environment variables in a scoped context for testing.
This package provides a collection of RuboCop cops to check for downstream compatibility issues in the Ruby code.
Mixed Treatment Comparison is a methodology to compare directly and/or indirectly health strategies (drugs, treatments, devices). This package provides an Rcmdr plugin to perform Mixed Treatment Comparison for binary outcome using BUGS code from Bristol University (Lu and Ades).
The Radiant Multivariate menu includes interfaces for perceptual mapping, factor analysis, cluster analysis, and conjoint analysis. The application extends the functionality in radiant.data'.
Facebook OAuth2 Strategy for OmniAuth
This package provides a shiny module to facilitate page layouts with resizable panes for page content based on split.js JavaScript library (<https://split.js.org>).
This RSpec plugin makes it easy to mark test cases as pending or skipped for a specific Ruby engine (e.g. MRI or JRuby) or version combinations.
Documentation at https://melpa.org/#/desktop-registry
Documentation at https://melpa.org/#/projectile-rails